
I came across this problem myself during summer when I was reading up on Azure Machine Learning. I had trained a ML experiment and when I was satisfied I wanted to generate a Web Service so I could utilize it in my business logic. However the model was trained from a huge CSV file with many columns which I had then cleaned inside the training experiment with R-Scripts or other ML tasks like “Select Columns in dataset” etc. But I quickly noticed that the generated web service (by default) generated input parameters for all the fields from the CSV. Fortunately, there are ways for you to adjust it but it wasn’t that easy to google an answer on this I hope that my post can help some of you.
So what was the problem with the default generation? In my case the default behavior was not OK.
- It would generate a bigger payload
- Would make the caller a bit confused on what was mandatory and what they need to enter to get the results they wanted. And as the training experiment included the answer column it would be very confusing to have that as part of the web service input already because the purpose of the service is to predict it based on the other parameters.
I also did not really appreciate the return values from the web service.
Note: I am in the scenario below deploying the web services using the classic model due to a Machine Learning ownership issue with a changed mail alias for my Microsoft Account (long story). You should probably use the new model if possible. In either case the choice is not of importance for the content of this post so I will show you the classic model instead.
First look at the solution, I start this example with a training experiment.
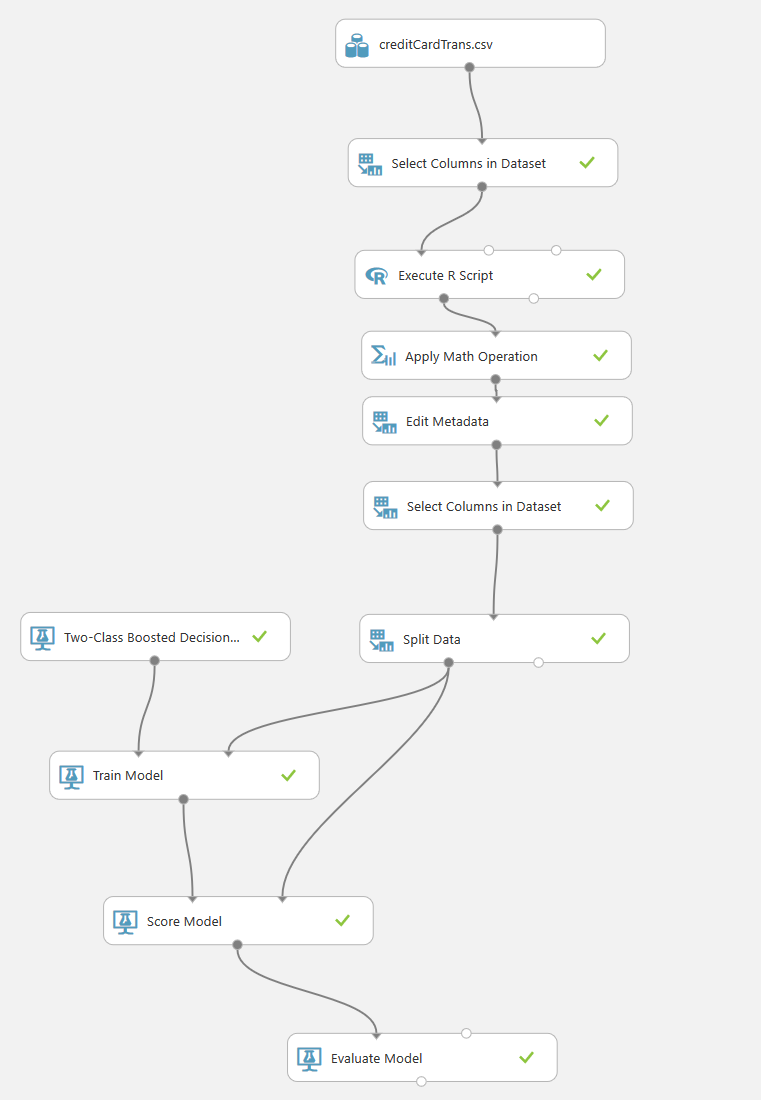
The trained model was based on the following columns in a CSV file which simulates a history of fraudulent and non fraudulent credit card transactions from people of various ages with credit cards issued in different countries and purchases being made in different countries and with different amounts. The end goal was to be able to predict the likelihood of a fraudulent transaction from, for example, Stream Analytics or an e-commerce site by calling the produced web services generated from ML (see previous post on how to do that).
The CSV file contains a lot of more or less useful columns. Which are then cleaned and modified in the training experiment.

So now that I am satisfied with my experiment I want to create a Web service from this experiment by clicking “Set up web service”-“Predictive Web Service”.

This will generate a predictive experiment. It you just accept the defaults and run and then publish the web service

The web service will by default it will give you all the columns from the source as input parameters which is undesirable in my case for several reasons like
- (Credit Card) IssuedCountry and (Credit Card) IssuedCountryCode are basically the same value. If both these are used in the experiment it would give aditional false security in the prediction so one should be stripped in the experiment and the web service should likely only accept the IssuedCountryCode and not the country full name.
- Same thing with (Purchase) UsageCountry and UsageCountryCode. Can’t have both and it will confuse users with having both as input to the Web Service.
- The name of the person (FirstName and LastName) likely has nothing to do whether the payment transaction should be predicted as fraudulent. For example I don’t think people named Fred will be more likely to fraud than people named Bob. There could be a statistical difference but we would likely not want to put any value into this.
- Another candidate could be City where the buyer lives may also be removed (unless we suspect that frauds are more likely in Manchester than Birmingham) which may or may not be statistically proven. But if the training data does not contain all cities we can’t predict how buyers from Brighton compares to the ones in the trained data.
- The training file had a flag saying whether the sample was a fraud or not (IsFraudulent). It does not make any sense to include this in the service as that is the result. After all If we already knew the answer we would not call a web service – right!
- I also have a classification field which is calculated in the logic in the Experiment. In the sample I group ages into different Age groups with an R script. As I don’t need to know if people aged 42 are more prone to generate fraudulent credit cards transaction than people aged 43 but rather see whether the fraud tendency of retired people, middle aged or young people could have any influence of the likelihood of frauds. When I interpret the result of any web service call it would be useful to know which category the person was evaluated under so I need that as a result as well.
- Lastly I would like to interpret the result 0 or 1 to a nice text before the web service returns.
Adjust the in-parameters
This is a bit tricky and you have to plan your experiment a little. By default, the web service input endpoint set at the top of the experiment (where your training document enters). This causes all columns from the CSV to be used in the web service as in parameters.
Your goal, if you want to adjust the parameters in the experiment, is to clean up the model you had as input in ML Studio and at some point end up with only the fields you want to use as input parameters to the web service. If you manage that – you can move your web service endpoint to that particular point and thus only get the remaining columns as input in your web service. I will show you what I did below.

In my case I wanted to send in only the important fields to be able to predict the likelihood of fraud. That would correspond to the following parameters to the web service
- (CreditCard) IssuedInCountryCode
- (CreditCard) UsageCountryCode
- Amount (Purchased)
- CreditRemarkFlag (if buyer has payment remarks)
- Age (Of Purchaser)
This should be sufficient for me to evaluate the likelihood of fraud (in my fictional scenario).
So to do this I will adjust my predictive experiment (not the training experiment). I add a “Select columns in dataset” task and select only my columns that I want to use as input. I then have to redraw the line from the web service to after my new “Select columns in dataset” task.
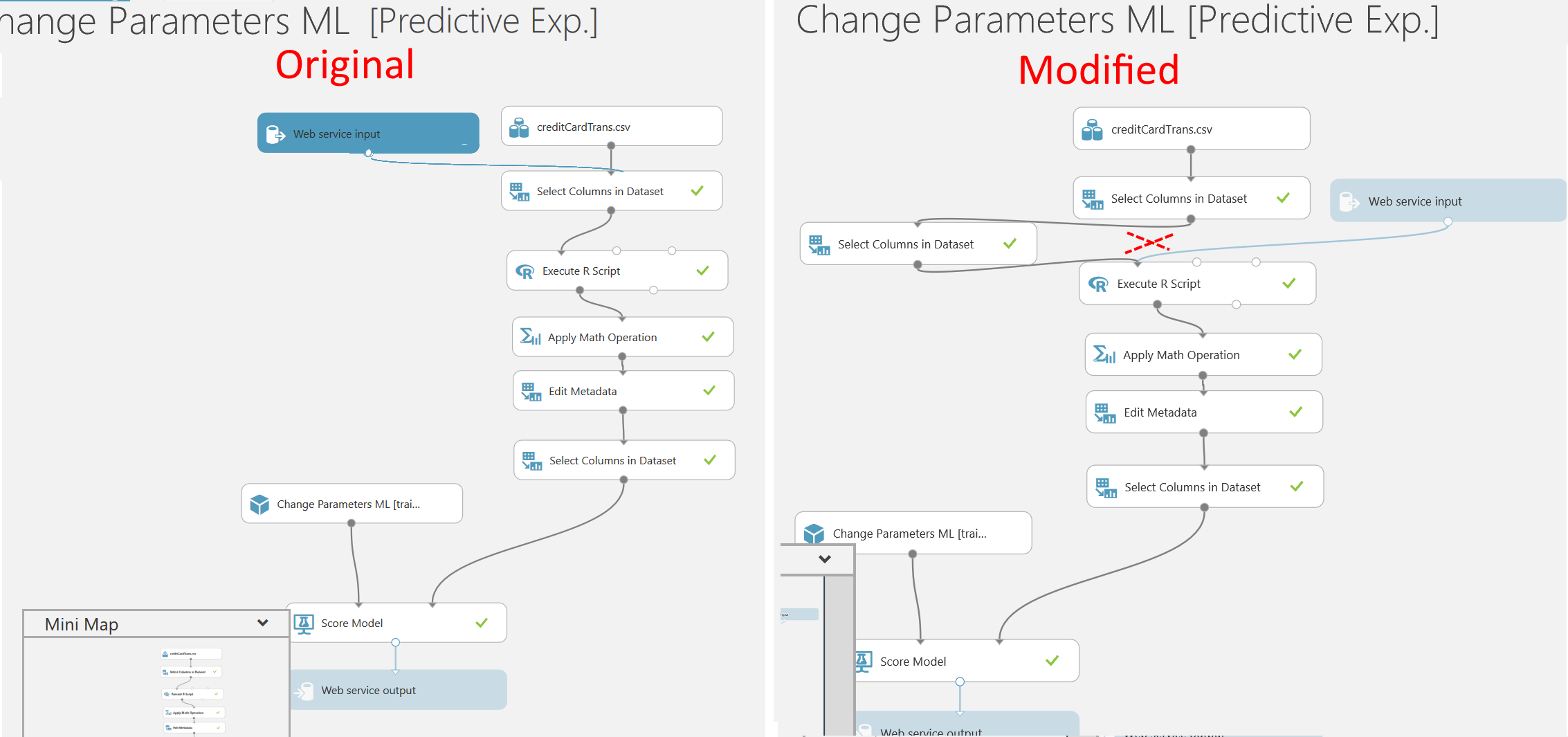
Note: In this case I could have done the column selection in the existing “Select columns in dataset” but as you (in some cases) might need to enter even later in the process I add a new “Select columns in dataset” task for to remove the unwanted columns to illustrate that you may have to modify the predictive experiment.
This will adjust the input of the web service. To test the correctness of the experiment you should run it. In my example I had to change some code in my R script later in the flow that handled the “IsFraudulent” column as I had now removed it in the new “Select columns in dataset”.
Once you can run the Predictive Experiment you should redeploy the web service.

After the adjustments the input parameters look like this

You may have to plan your experiment much more to get the web service definition that you desire. Maybe you want to adjust the experiment even further by running some R script to transform the data before your web service invocation is best suited to be started. The solution is still the same though, you modify the data representation and connect the web service input to a certain desired point in your experiment. It could also be that in some cases that you will have difficulty to get the web service to have the exact interface that you desire depending on the logic in the experiment itself which means that you may have to add more or less R logic to get it to work.
Adjust the out-parameters
So now that we have the input parameters right it is time to turn to the output parameters.
The default web service has generated the following columns.

Adjusting the out parameters is a bit more straightforward. Basically your end result (likely the lower-most box defines the output) will be returned (i.e. all columns that was still used and the predicted results). So your goal here is just to make sure that you have removed any unwanted columns from the “dataset” and have added the any needed calculated ones during the processing before your flow is ended.
- In my case you remember that I wanted to return some label based on the result like “Likely Fraud” and “Unlikely Fraud” instead of just 0 and 1. To do this I add a R script after the evaluation. I create a new column based on “Scored Labels” and then I remove the “Scored Labels” column.

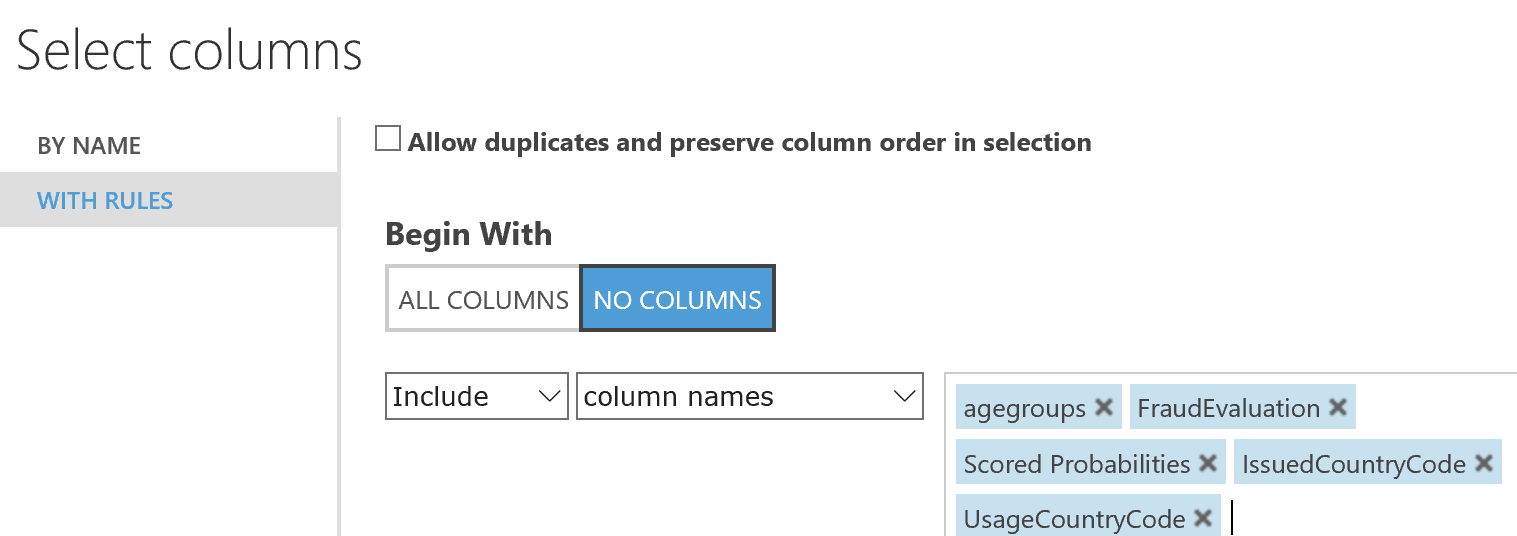
- In my scenario I wanted to return the bool value whether the experiment indicated possible fraud, the calculated probability and what age category the person was classified as. I don’t need all the parameters that I used to call the web service anymore so they can be removed. So I added a “Select columns in dataset” task in the end and selected only the desired columns.

Select Output columns for WS
The predictive experiment now looks like this.

And so when I run the experiment without errors and re-deploy it one can see the signature of the output changed to the following definition.

Test the modified Web Service
The web service is now ready to be tested. The easiest way to do this is through the portal. Just select the web service and press the test button.
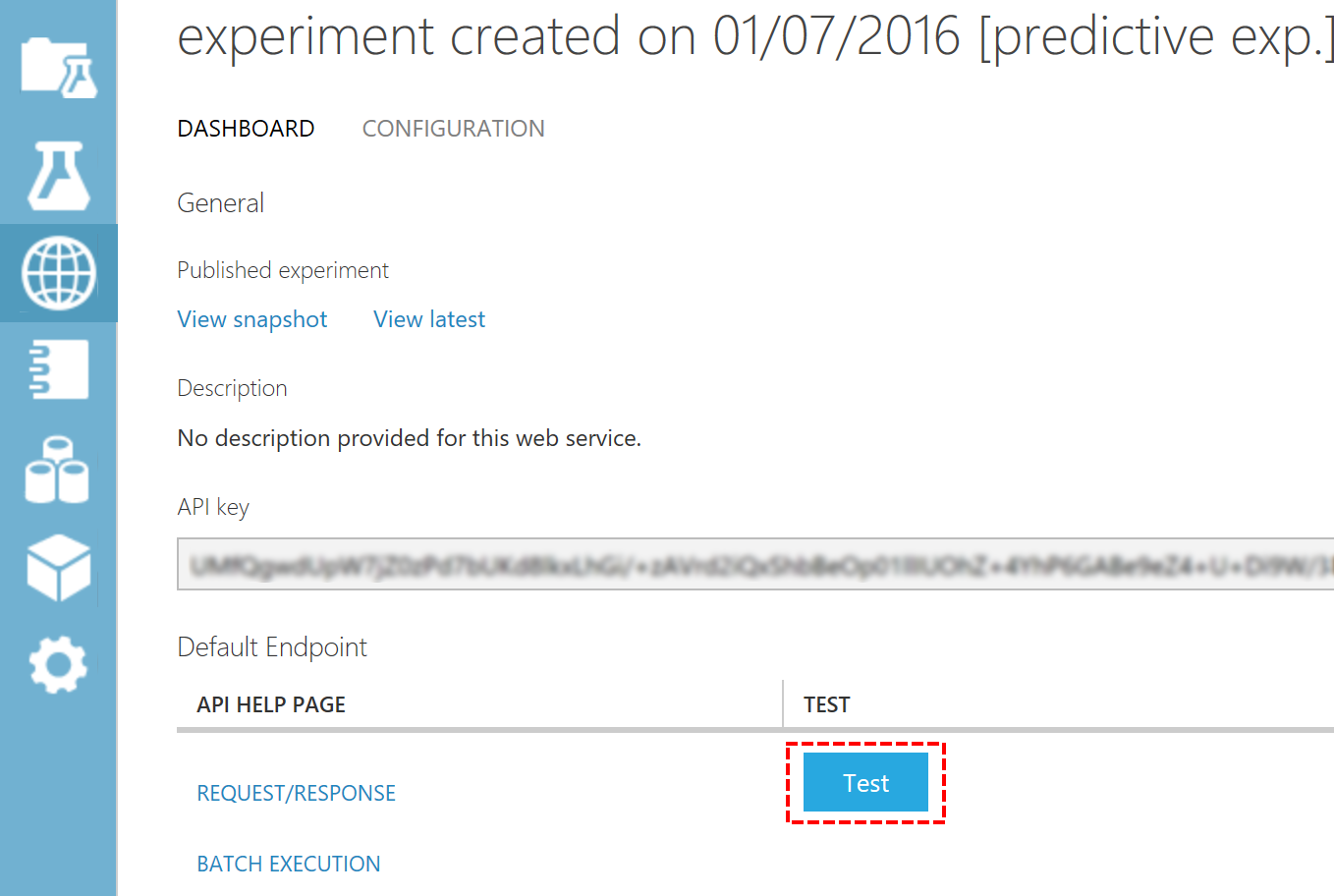
You will now see a simple entry form for you to fill in your values. Verify that they are the modified version of input parameters otherwise you have probably forgot to re-deploy your web service.

After you submit the form it will process and you will get the result in the lower part of the screen. Verity your output parameters.

You are now ready to incorporate your modified and business aligned web services to your applications or Stream Analytics processes (see how to do this in a previous post Call Azure Machine Learning Experiments from Stream Analytics)


I’m getting the below error, can you please help me out:
Score Model Error
AFx Library library exception: table: The data set being scored must contain all features used during training, missing feature(s): ‘PowerScout’, ‘Temperature’, ‘Visibility’, ‘Daily_electric_cost’, ‘kW_System’. . ( Error 1000 )
LikeLike
Hi. It is difficult to say based on this input. It sounds like (and is a possible scenario If you have tried to follow my post) that you have removed columns like PowerScout, Temperature in the web service input so that they are not present in the dataset but are still used in your logic somewhere.
LikeLike
Thanks Peter for your solution. I had a same issue, but with your ‘Select the input/output in Predictive experiment’ approach, i could eliminate my issue.
LikeLike
Great and thorough post. You had the exact same situation as me. Now I’m able to use the correct web service parameters.
LikeLike